Cookies Disclaimer
To comply with the EU regulation, you are informed that tiny text files (cookies) are saved on your device for technical purpose. You can disable them by changing the settings of your browser.
Welcome!

... nice to have you visiting ...
Pick a topic, and see what's inside.
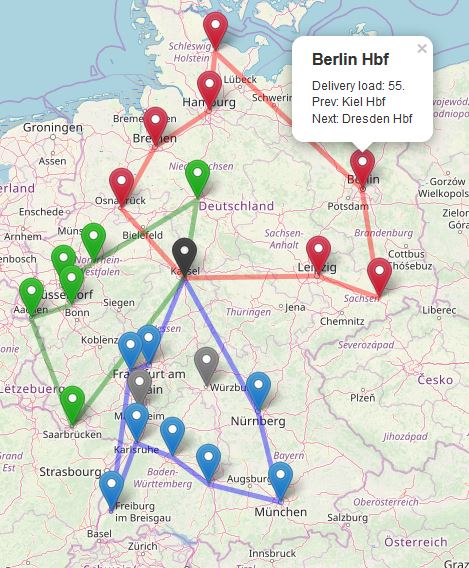
This page illustrates a logistics case to visit multiple nodes (cities) once and only once each, while minimizing the cost. Here, a delivery vehicle can only carry a limited volume, unable to satisfy all customers with a single tour.
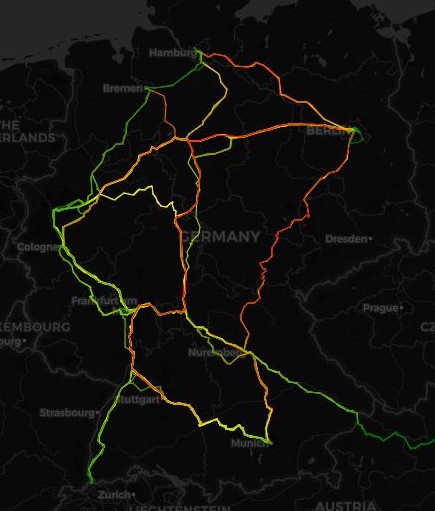
Wifi user heatmap in Germany's ICE train, as available here. Pre-processed from millions of rows, only 25 routes are displayed here. Information regarding route and stops of each train can also be extracted.

You think bot is a brainless little creature? Big mistake. After drinking some potion of Convolutional Neural Network, an unselfish Telegram bot can definitely outsmart you. Coming soon! 🤖
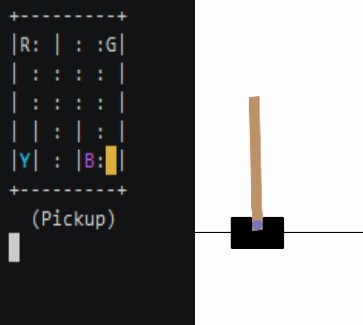
The research company OpenAI composed a number of environments in a so-called Gym. Suitable as algorithmic benchmarks, we solve some scenarios here using Reinforcement Learning. Step by step.
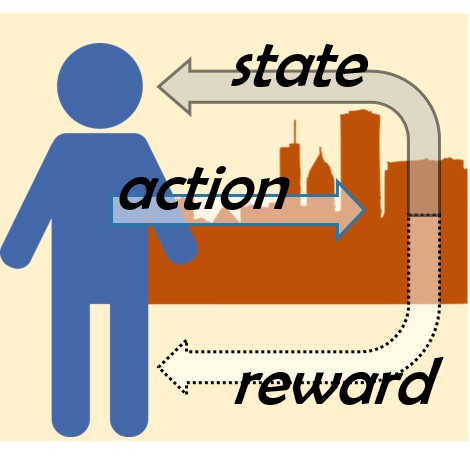
Reinforcement Learning: let's start off with some dummy-mode comparison between the ANN and XCS-RC algorithm in classifying Churn Modeling data. So, bank customers, are you in or out?
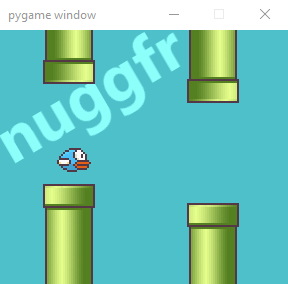
Rewinding all the way back to my dissertation, I want to help that (once) famous Flappy Bird avoiding those deadly pipes! The little one can even learn to reach over 9999 points, if we guide it right! 😏