
Reinforcement Learning with Flappy Bird
Survival of the Flappest! 💪😁
Everyone knows Flappy Bird! In
case you
do not, just take a look at the image here.
 So, the bird flaps in a Mario-like world. But instead of entering or exiting the pipes, it should
avoid
them. All of them, including the ground, and the top limit of the screen. The problem, lies in the
gravity.
Without flapping, the bird go down vertically, while the pipes are always moving from the right side
of the
screen, to the left. A flap would make it go up, but not for long.
So, the bird flaps in a Mario-like world. But instead of entering or exiting the pipes, it should
avoid
them. All of them, including the ground, and the top limit of the screen. The problem, lies in the
gravity.
Without flapping, the bird go down vertically, while the pipes are always moving from the right side
of the
screen, to the left. A flap would make it go up, but not for long.
Commonly played in a touch screen device where a tap make the bird flaps, this time an action is
regulated
by a Reinforcement Learning (RL) mechanism, with two possible outpus: flap or no. The input
states are
composed by observing the screen along with an internal state of the bird's current vertical
position.
For the RL algorithm, an instance of XCS-RC is used, can be downloaded using pip install
xcs-rc
or at github.
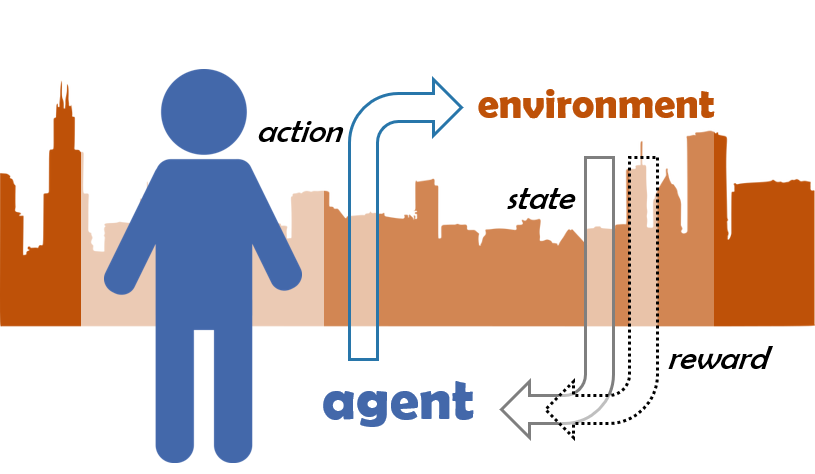 Reinforcement Learning is a way of collecting a set of knowledge through experience. An agent
observes the
environmental state, and then acts upon it. Then the decision is judged by a reward,
denoting the action's appropriateness to the previously given state. The feedback closes an RL
cycle,
and the next one begins when an input state is received by the agent.
Reinforcement Learning is a way of collecting a set of knowledge through experience. An agent
observes the
environmental state, and then acts upon it. Then the decision is judged by a reward,
denoting the action's appropriateness to the previously given state. The feedback closes an RL
cycle,
and the next one begins when an input state is received by the agent.
Thanks to the Flappy Bird game maintained by pygame, we can focus on the learning part without too much effort in
managing the design.
As usual, the very first step is getting the environmental states. At first, we will do that using a
built-in
getGameState() function, since it is the easiest way. But then, some non-learning image
processing stuff will be added to get more fun. 😉
This earliest step requires at least two parts: initializing the game environment (FlappyBird) and the learning agent. Below are the codes for the former.
#game_initialization
from flappybird import FlappyBird
game = FlappyBird()
from ple import PLE
p = PLE(game, display_screen=True)
p.init()
actions = p.getActionSet()
print("Available actions:", actions)
A successful initialization is indicated by two outputs: a pygame window, and a console output similar to below, where the pygame version may differ:
pygame 1.9.6
Hello from the pygame community. https://www.pygame.org/contribute.html
Available actions: [None, 119]
Here, None represents no flap while
119 is a code for do flap.
Then, we initialize the learning agent using an XCS-RC
instance.
# xcs_initialization import xcs_rc agent = xcs_rc.Agent() agent.maxpopsize = 200 agent.tcomb = 100 agent.predtol = 5.0 agent.prederrtol = 0.0
Using a one-liner like agent = xcs_rc.Agent(maxpopsize=200,
...) is also possible, depending on anyone's preference.
The current states of the screen can be
obtained
with the function getScreenRGB().
# get_screen_states screen = game.getScreenRGB()The window size for the Flappy Bird game is
288x512 pixels, making an overall of 442386
values,
all within the range [0..255]. Further processes will be provided below.
This is how we get the game states the easy way. The variable
pipe_y is added with 50 as the gap between a pair of pipes is 100
pixels.
# get_game_states game_state = p.getGameState() bird_y = int(game_state["player_y"]) bird_v = int(game_state["player_vel"]) pipe_x = int(game_state["next_pipe_dist_to_player"]) pipe_y = int(game_state["next_pipe_top_y"] + 50)
And, the observation part is actually done. The values of these
states will
be fed to the bird, as it should make decisions to execute do flap or do not
flap.
Now let's get the bird's action by feeding the states to the learning system, and then execute
the action
to the environment. The variable state is a list consisting of three values:
- the next pipe's absolute distance, from the left-hand side of the screen
- the next pipe's relative vertical distance to the bird, and
- the bird's current vertical speed
# compose_state state = [pipe_x, (bird_y + 12) - pipe_y, bird_v]
I have tested to make the bird learning only with the first two values, but the result was not
quite satisfying. A small number of states is decisive for reaching an optimal learning speed.
And, since three is not that much, I think we're good to go.
😎
By the way, why is there a 12 added to bird_y?
Well, it is actually optional, and the idea is to store the middle value of the bird's height,
which is 24. So, we do not use the top position of the image, but the middle instead.
And now, let's get to the action, and execute it.
# get_agent_action, 0 = no flap; 1 = do flap action = agent.next_action(state) # execute_action p.act(actions[action])
Want to see what some lines of codes can give?
You got it. This is the du... not learning version of our Flappy
Bird.
😁
# game_initialization here
# xcs_initialization here
from time import sleep
NUM_RUNS = 10
while game.player.runs < NUM_RUNS:
game_state = p.getGameState()
bird_y = int(game_state["player_y"])
bird_v = int(game_state["player_vel"])
pipe_x = int(game_state["next_pipe_dist_to_player"])
pipe_y = int(game_state["next_pipe_top_y"] + 50)
state = [pipe_x, (bird_y + 12) - pipe_y, bird_v]
action = agent.next_action(state)
p.act(actions[action])
# reward assignment will be placed here
# to prevent it becoming a Flashy bird 😵
sleep(0.01)
if game.game_over():
game.player.runs += 1
game.reset()
And here's the result:Because the chance of
do flap and no
flap is equal at 50:50. However, the difference is, once it choses do flap,
performing no flap would give no effect for the next 8 ticks, since it will still go up
anyway. On the other hand, picking do flap make the flappy bird even closer to hit the
ceiling.
Composing the reward map is commonly quite difficult, but also a very important part in the whole
Reinforcement Learning, especially when facing dynamic environments. For this one, we will do it
as simple as possible, but yet providing an outstanding result.
So, the feedback for each action would be determined by two factors:
y= the bird's relative vertical position to the nearest pipediff= the difference from the previousy
if 9 <= y <= 35:
reward = maxreward
The first formula is pretty straightforward: set the full reward value if y is
greater than or equal to nine, with a maximum at 35. The idea of these values is to keep the
bird at the lower half of the pipe gaps, as often as possible. By doing that, we minimize the
risk of hitting the upper pipe when flapping. The second and third formula have something to do
with the diff variable:
else:
# calculate the vertical difference from center
center = 22
from_center = abs(y - center) - abs(y - diff - center)
# if the bird is getting closer to center
if abs(y - center) < abs(y - diff - center):
reward = (0.5 + abs(from_center) * 0.05) * maxreward
# otherwise, if it is going away
elif abs(y - center) > abs(y - diff - center):
reward = (0.5 - abs(from_center) * 0.05) * maxreward
And that's it! Based on only these lines for determining the reward, the flappy bird will be able
to learn flapping through thousands of pair of pipes. At the video, it's only around 1200 points
max. After some algorithmic improvements, more than 10000 pair of pipes can be solved,
still under 100 episodes.
However, very important, never forget to assign the reward and update the executed rules with a
single line of code...
agent.apply_reward(reward)Now, if you are looking for a simple way to beat flappy bird, it is done. But as I said, using the provided internal states is too easy. Image processing would be the next challenge. And to keep it simple, no learning algorithms will be used for that. Just a bunch of simple math.
Keep checking this page out, they might be here sooner than you thought. 😉