OpenAI Benchmark Problems
CartPole, Taxi, etc. | still in progress
In Reinforcement Learning (RL), OpenAI Gym
is known as one of the standards for comparing algorithms. Therefore, this page is dedicated
solely to address them by solving the cases one by one. Starting from the Cart-Pole
environment representing a simple control theory case, and then Taxi which is an
instance of a hierarchical learning.
We will go even further to see how other available
scenarios can be solved using XCS-RC. All codes will be presented as simple as
possible, without reducing the important factors.
pip
install xcs-rc or via github to get the required library.
I remember the first time studying this inverted pendulum problem at my bachelor study, which is very unsurprising because I came from the Control Engineering background. CartPole has a similar characteristics, and what we need as a start is a set of environmental states.
xcs_input is created for that purpose. See corresponding
notes on the right column for some detailed explanations.
state = env.reset() # executed once when an episode begins
for t in range(200): # episode starts here
xcs_input = [state[1], state[2]]
action = agent.next_action(xcs_input, 2) # explore_it
action as a
response for the given state. Now we will drive the cart to act accordingly.
state, feedback, done, info = env.step(action)
env.render() # draw image
The value of state has a similar structure to that returned by
env.reset() above. Other than that, we will only use done, which
indicates an end of the current episode.
- Current pole angle (straight up 0° as reference)
- The difference to previous value
reward = 0.0 # initialize reward
if state[2] * (action - 0.5) >= 0.0: # if getting closer to reference
reward = 0.8 # set good reward
if abs(state[2]) < 0.05: # if very close to reference
reward += 0.2 # make it higher
agent.apply_reward(reward * agent.maxreward)
Of course, there are many ways to improve the reward calculation, like taking the cart's
momentum into account. However, here we want to make it simple, and XCS can still learn well.
done
== True.
if done:
t += 1 # +1 since it starts from 0
break # break the loop
# episode ends here
print("Finished after {} timesteps.".format(t))
So, that's it?
Yes, basically that is it. The cart will learn to keep the pole in a straight-up position using RL. Of course, one episode is insufficient. For a complete version quite similar to this one, you can check out my github page. It's way easier than you thought! 😉
XCS-RC
and the environment have to be initialized. This is how we do it.
import xcs_rc
import gym
agent = xcs_rc.Agent(tcomb=10, prederrtol=0.0)
agent.reward_map(max=1000.0, projected=800.0)
env = gym.make('CartPole-v0')
An environmental state is a list (array) consisting of four elements:
- Cart: position
- Cart: velocity
- Pole: angle
- Pole: velocity At Tip
Cart: velocity and Pole: angle to solve the
problem.
This function finds all rules in the
population of knowledge that match state and returns the selected action using a
method determined by the second parameter. The available options are:
explore: pick inexperienced rules as priorityexploit: always choose the ones with high predicted rewardexplore_it: combination of both above, doexplorewhenexploitpredicts a reward less than projected (determined inagent.reward_map())
Carelessly using the term
reward in CartPole environment might cause a small confusion. Why? Because there
are two kinds of rewards: from the environment to the agent, and from the agent to the rule.
They are two entirely separate instances. To prevent that, I will consistently use the word
feedback for the former and reward for the latter.
This is already available at youtube for everyone to watch! Have a nice balance! 😎
Now we tackle a problem involving a hierarchical RL, or in XCS, it is called multistep.
As the title suggests, an agent should pick-up a passenger at a certain point and then do a
drop-off at another. In this
environment, four locations are available for picking up and dropping off.
The "world" has 25 coordinates available, along with six possible actions for directions and
passenger-related (SNEW/PD). An environmental state consists of [taxi_row, taxi_col,
passenger_location, destination] with 5 x 5 x 5 x 4 = 500 possibilities.
Put together the actions, we get 3000 available pairs of state-action.
CartPole, composing an input structure
in Taxi quite takes some time (actually not that long, I solved this case in less
than a workday in total). The trick is to set the number of elements as small as possible,
while still represents the whole problem. Before doing anything, don't forget to initialize.
def get_input(obs):
target = obs[2] if obs[2] < 4 else obs[3] # get current target
if obs[:2] == loc[target]: # obs[:2] is taxi's position
return [-1, -1] + [obs[2]] # return special state
else:
return obs[:2] + [target] # return normal state
What can we conclude from the code?Well, basically, the function
get_input(obs) where and what the taxi should do. The
value obs[2] < 4 means that a passenger is waiting. So, we set the target following
the passenger's location. Otherwise when the passenger is already in the taxi obs[2] ==
4, the target is the drop-off's location.What is that special state? That is a trick to make XCS learn quicker. By giving a pair of negatives in taxi's coordinate, XCS can quickly get the idea that now is the correct place to pick-up or drop-off the passenger. 😉
Afterwards, we take and decode the first observation, and start the episode.
obs = list(env.decode(env.reset())) # decode first observation
# episode starts here
for t in range(200): # 200 steps before giving up (important!)
state = get_input(obs)
Cart-Pole that allows us to apply a
straight-forward action and reward, here comes the tricky part of multistep learning. It is
called delayed reward, and it is very effective. Basically it says, "if the
agent has not reach the target, give a discounted reward out of the highest possible
afterwards". Corresponding note on the right column might help. 🙂
agent.build_matchset(state) # collect matching rules
action = agent.pick_action_winner(2) # pick a winner with explore_it
# delayed reward function here
agent.build_actionset(action) # collect winning rules
A small number of lines is reserved for the delayed reward. For now, let's just focus on the
conventional steps: get matching rules, pick a winning action and collect corresponding
rules.
prev = state # keep state for a later comparison
obs, _, done, _ = env.step(action)
obs = list(env.decode(obs)) # decode given observation
env.render() # draw image, optional
The value of state has a similar structure to that returned by
env.reset() above. Other than that, we will only use done, which
indicates a successful drop-off.
Taxi employs two types
of reward function:
- Normal, when the agent reaches the target
- Delayed, for otherwise
This is how we judge the normal reward.
if (prev[2] < 4 and state[2] == 4) or done:
agent.apply_reward(agent.maxreward)
elif prev == state:
agent.apply_reward(0.0)
The code basically tells us, a maximal reward is obtained when the passenger is picked-up or
droped-off properly. Contrary to that, the lowest gain is awarded when no progress occurred,
inidicated by an unchanged state (e.g., caused by hitting a wall).And, what about the delayed reward?
Simply put this code to the corresponding comment before building action set, and it's done.
# this is the delayed reward
if agent.aset.size() > 0: # if action set is not empty
agent.apply_reward(agent.gamma * max(agent.pa))
If no normal reward given, then assign a delayed one. To fully understand these tricks, you
probably need to learn XCS-RC algorithm. Some notes on the right column here might
help a little, but we'll see. For now, I suppose there is only one thing left to make the code
up and running:
done == True.
if done:
t += 1 # +1 since it starts from 0
break # break the loop
# episode ends here
print("Finished after {} timesteps.".format(t))
Gets a little tough?
Don't worry about it. A little reading and some coding exercise would make you understand better and able to improve the algorithms. Remember to make the agent learns hundreds of episodes or more, instead of only one like the example here. Then, it might become a smarter taxi learner! 😎
XCS-RC
and the environment have to be initialized. Here, the locations of passenger and target is also
initialized.
import xcs_rc
import gym
agent = xcs_rc.Agent(num_actions=6, predtol=5.0)
agent.reward_map(max=100.0, projected=81.0)
agent.beta = 0.7 # learning rate
agent.gamma = 0.8 # discount factor for multistep
env = gym.make('Taxi-v2')
loc = [[0, 0], [0, 4], [4, 0], [4, 3]]
An environmental state here consists
of only a number in [0..499] and therefore should be decoded using env.decode(state).
The result is an array of four elements:
- Taxi: row
- Taxi: column
- Passenger: location
- Dropoff: location
[0..3]. Once entering the taxi, the value
will be 4.
This function finds all rules in the
population of knowledge that match state and returns the selected action using a
method determined by the second parameter. The available options are:
explore: pick inexperienced rules as priorityexploit: always choose the ones with high predicted rewardexplore_it: combination of both above, doexplorewhenexploitpredicts a reward less than projected (determined inagent.reward_map())
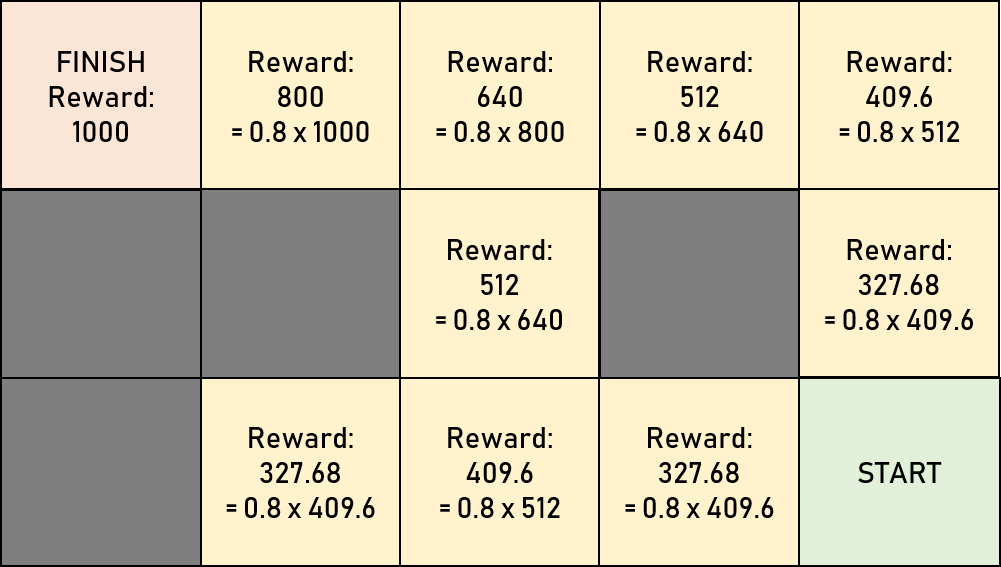
It is a common technique in RL to
guide a learning agent performing a set of expected steps. For instance, if reaching finish
gets a maximal reward at 100.0, then moving into one cell away from finish would
be rewarded with agent.gamma x 100.0 which in this case is 80.0.
Calculations for other cells are similar to that, as depicted below.
In other words, the current reward is assigned after calculating the highest
next reward possible for the new cell, discounted by agent.gamma.
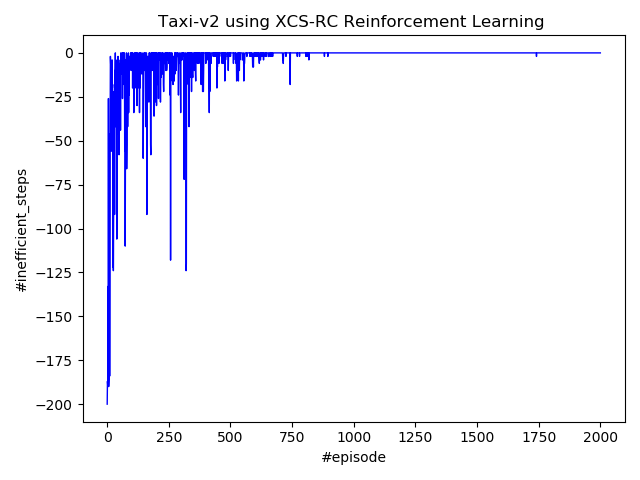
So, since the provided display is a text world instead of graphics, it might be a little unworthy to record a video. Instead, this figure of #inefficient_steps might give you an impression of how the taxi behaves.